
In the relentless churn of generative AI content pipelines, watermarks stand as crucial barriers against rampant misuse, from deepfake proliferation to intellectual property theft. But here's the pragmatic truth: these markers are increasingly fragile, with adversaries wielding advanced attacks that strip them away effortlessly. Preventing AI watermark removal isn't just a technical challenge; it's a strategic imperative for creators and platforms alike, ensuring generative AI watermark permanence in an era where synthetic media floods every corner of the digital landscape.

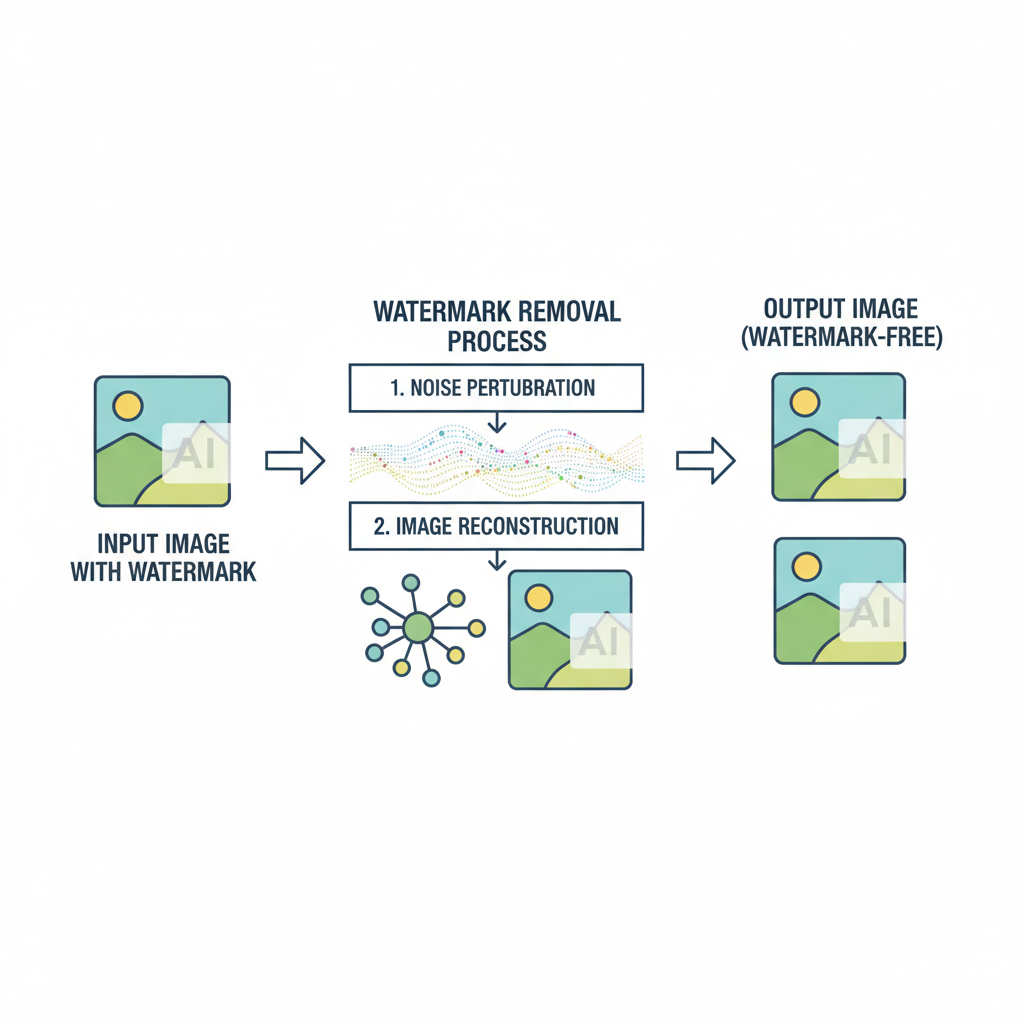
Recent breakthroughs in adversarial research paint a stark picture. Papers from arXiv detail how pre-trained diffusion models paired with GANs can erase watermarks from AI-generated content, effectively laundering synthetic outputs for illicit use. NeurIPS 2025 findings go further, proving that invisible image watermarks are removable through a simple two-step ploy: inject random noise to obliterate the signal, then reconstruct the image with high fidelity. This flexibility means no watermark is safe from determined attackers, wiping out up to 99% of embedded signatures as noted by ScoreDetect analyses. Even detection systems falter, with ACM studies evading watermark-based checks on AI images through subtle perturbations.
Shield AI Pipelines: Block Watermark Removal Attacks


Exploits Exposed: Diffusion Denoising and Beyond
At the heart of these threats lies diffusion denoising, a cornerstone of modern generative models. Attackers exploit this by reversing the generation process; noise addition destroys delicate watermark patterns woven into pixel distributions or latent spaces. GitHub's Awesome-GenAI-Watermarking repo curates dozens of such methods, underscoring how watermarking, once hailed for embedding imperceptible yet recoverable signals, now contends with forgery too. Forged watermarks misattribute content, sowing chaos in authenticity verification. Adobe communities buzz with pleas for low-opacity color overlays harder for AI tools to detect, yet these visible hacks merely delay the inevitable against sophisticated GAN erasers.
Pragmatically speaking, relying solely on invisibility is a fool's errand. Human eyes might miss the mark, as Medium's Adnan Masood explains in dissecting hidden signatures meant to tag AI origins resiliently. But machines don't blink; they probe frequencies, gradients, and statistical anomalies with ruthless precision. Hugging Face's Watermarking 101 lays bare the pros and cons: tree-based or frequency-domain methods shine in clean pipelines but crumble under compression, cropping, or color shifts common in real-world distribution.
RAW Frameworks and Latent Code Defenses: Toward Unremovable Watermarks
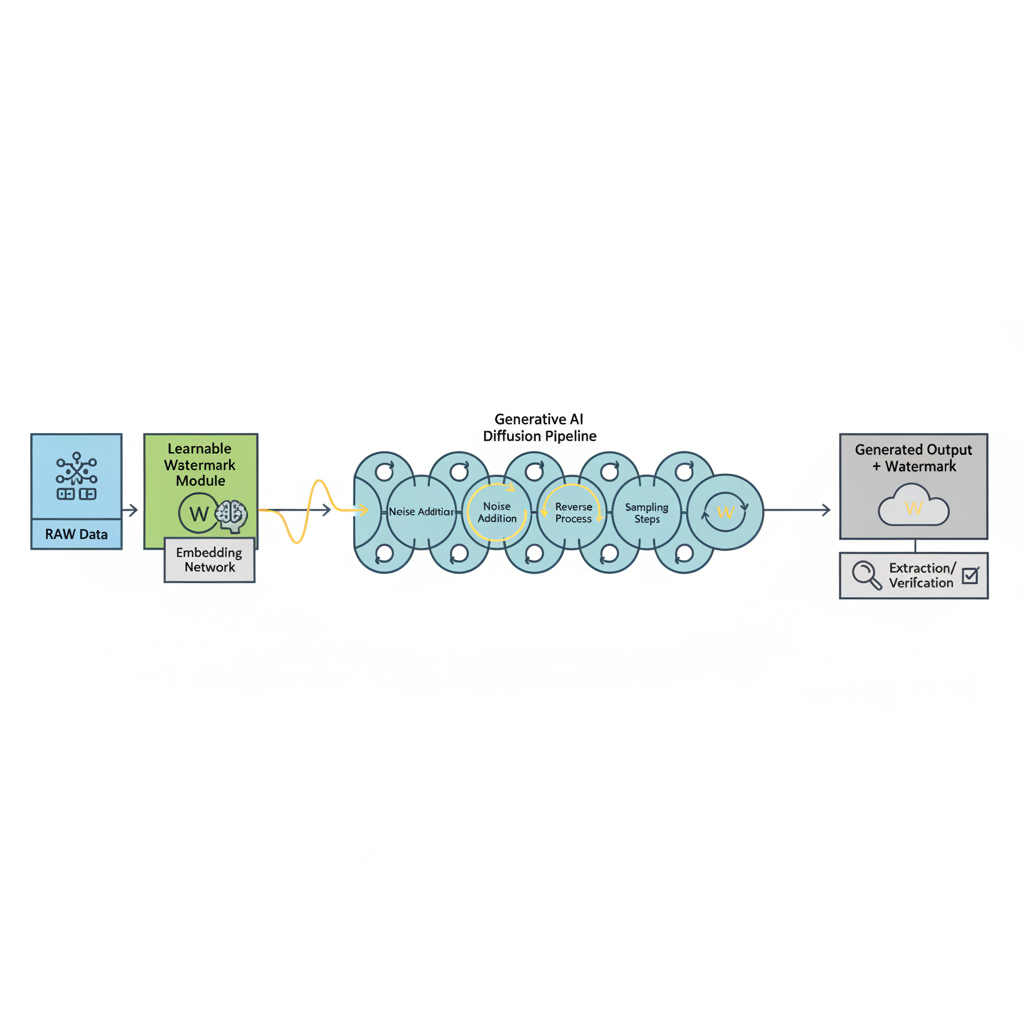
To counter this, forward-thinking frameworks like RAW flip the script, baking learnable watermarks directly into image data alongside classifiers tuned for detection. This dual-layer approach resists both removal and forgery, thriving even post-attack. Similarly, pseudorandom error-correcting codes guide initial latents in diffusion models, yielding undetectable embeds that preserve quality while repelling denoisers. ICLR's GenAI Watermarking workshop echoes this shift, embedding signals across text, images, and audio for holistic ownership proofs.
These aren't pie-in-the-sky ideas; they're deployable now in unremovable watermarks AI pipeline setups. Imagine pipelines where watermarking triggers at generation, verified at every handoff. Yet, debates rage: is watermarking enough against misinformation tides? Experts wisely pair it with multi-modal checks, but for synthetic content protection rails, it's non-negotiable. The COPIED Act bolsters this legally, criminalizing tampering with AI origin data, yet enforcement hinges on robust tech first.
Pipeline Integration: Embedding Resilience from Source
Start upstream. Integrate watermark encoders into your generative stack - Stable Diffusion, DALL-E derivatives, or custom LLMs for text. Use ECC-infused latents to sidestep common pitfalls; tests show 90% and survival rates against noise attacks. Classifiers then patrol outputs, flagging dilutions before export. For video and audio, extend to temporal or spectral domains, where ICLR methods prove durable against frame edits or pitch shifts.



No comments yet. Be the first to share your thoughts!