
In an era where a simple 'Hi!' can launch a sophisticated scam, the stakes for audio deepfake detection have never been higher. Imagine receiving a voice message from a trusted colleague, only to discover it's an AI-forged impersonation designed to extract sensitive information. Recent research underscores this vulnerability, showing that deepfakes can deceive even under real-world degradations like noise or compression, especially in ultra-short clips of 0.5 to 2 seconds. This is where audio deepfake watermarking emerges as a conservative bulwark, embedding imperceptible markers to verify authenticity from the first uttered word.

Traditional detection methods falter when audio is truncated or distorted, as highlighted in studies from the University of Exeter and arXiv papers focused on synthetic speech first greeting detection. These works reveal that passive forensics struggle with the speed and subtlety of modern generative models. My view, shaped by years of safeguarding assets, aligns here: protect integrity first, innovate second. Proactive watermarking flips the script, proactively signaling synthetic origins without altering perceptible quality.
Watermarks That Whisper Truth Amid Audio Chaos
Imperceptible sound watermarks function by weaving hidden signals into the audio spectrum, often in frequencies beyond human hearing or modulated to survive edits. Meta's recent system, for instance, embeds these signals into AI-generated speech, enabling detectors to flag fakes proactively. Similarly, Facebook's AudioSeal localizes watermarks at every sample, outputting probabilities down to 1/16th of a second. This precision matters in greetings, where the opening syllable sets the trap.
From a methodical standpoint, these tools outperform reactive classifiers. USENIX research on audio watermarking for deepfake speech detection emphasizes explainable predictions, a feature that builds trust. Resemble AI's PerTh watermarker adds unique identifiers, making unauthorized cloning traceable. In my conservative assessment, such layered defenses mitigate risks without overcomplicating workflows for creators.
Real-World Benchmarks and Corporate Shields
The FakeSound2 benchmark pushes boundaries, evaluating models on localization, traceability, and generalization. It exposes gaps in current detectors, particularly for short bursts like initial greetings. Companies are responding: Watermarked. ai deploys undetectable watermarks to poison AI training data, thwarting deepfake generation at the source. Noiz AI's cloned voice service ensures synthetic assets carry robust, inaudible markers for authenticity checks.
Key Audio Watermarking Advances
- Meta's Hidden Signals: Embeds imperceptible watermarks in AI-generated speech for proactive detection.

- AudioSeal Localization: Facebook Research tool detects watermarks at sample level (1/16k second) in audio waveforms.

- Resemble AI PerTh: Neural watermarker embeds unique inaudible data into synthetic voices for verification.

- Watermarked.ai Poisoning: Undetectable watermarks disrupt unauthorized AI training and enable deepfake detection.

- FakeSound2 Benchmarks: Evaluates deepfake detection models on localization, traceability, and generalization.
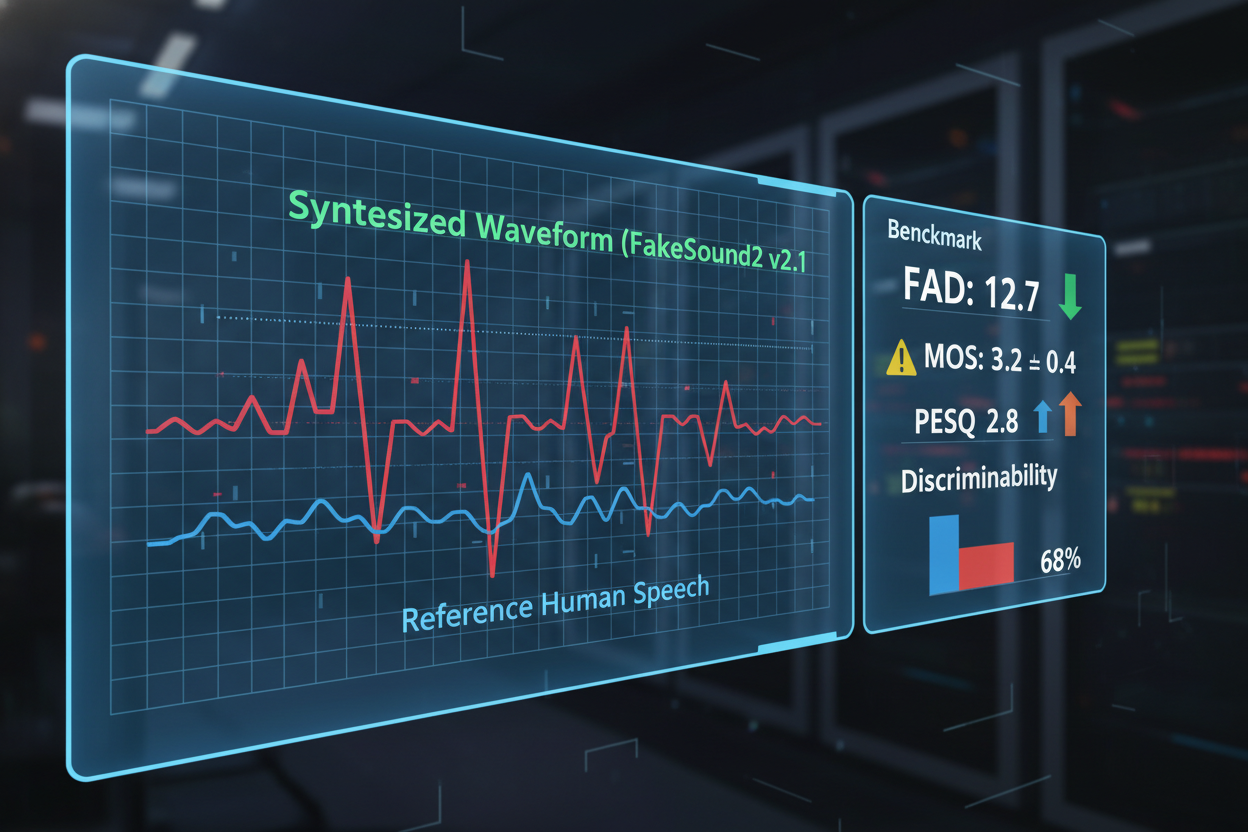
These innovations dovetail with platforms like AI Watermark Hub, where AI audio royalty rails integrate seamlessly. Creators watermark content at generation, track distribution, and enforce royalties automatically. It's a prudent ecosystem: detect fakes early, monetize ethically, and hedge against misuse.
Precision Detection from the First Phoneme
Ultra-short input challenges demand watermark designs robust to compression, reverb, and bitrate drops common in calls or social media. ResearchGate analyses confirm that first-greeting detection hinges on spectral anomalies imperceptible to ears but glaring to algorithms. AudioSeal's per-sample output, for example, flags watermarks in real time, ideal for live verification.
Opinionated take: Relying solely on post-hoc analysis is reckless; embed safeguards upfront. Proactive forensics, as detailed in ScienceDirect papers, shift paradigms from whack-a-mole detection to fortified origins. For media firms and developers, this means watermarking as standard protocol, akin to digital signatures on bonds.
Audius Technical Analysis Chart
Analysis by Sarah Davis | Symbol: BINANCE:AUDIOUSDT | Interval: 1W | Drawings: 6
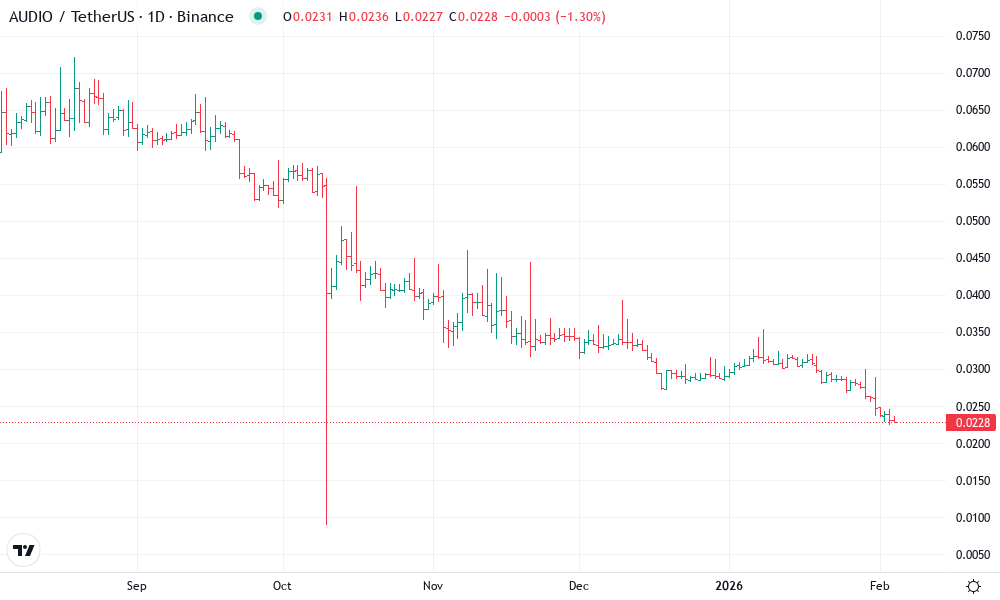
Technical Analysis Summary
As Sarah Davis, with my conservative, capital-protection-first approach honed over 18 years in risk management, I instruct drawing the following on this AUDIOUSDT chart: Use 'trend_line' for the dominant downtrend connecting the January 2026 swing high at approximately 0.580 to the late February 2026 pullback high near 0.230, highlighting the bearish channel. Add 'horizontal_line' tools at key support level 0.170 (strong) and resistance levels 0.250 (moderate) and 0.400 (strong). Draw a 'rectangle' for the distribution price range spanning mid-January to late February 2026 between 0.450 and 0.180. Mark volume spikes on declines with 'arrow_mark_down'. Place 'callout' on the MACD bearish zone below zero and recent breakdown. Use 'text' for notes on low-risk entry zone near 0.175 only if support holds, and 'arrow_mark_up' cautiously for potential fundamental-driven bounce tied to audio tech news.
Risk Assessment: high
Analysis: Volatile crypto asset in confirmed downtrend with bearish volume/MACD confirmation; downside risk outweighs upside without reversal signals, amplified by market volatility.
Sarah Davis's Recommendation: High risk—stay sidelined in safer assets like short-term bonds. Protect capital first; monitor for bullish engulfing at support with volume before considering low-risk entry.
Key Support & Resistance Levels
📈 Support Levels:
- $0.17 - Strong support at cluster of recent lows and approximate psychological level strong
- $0.2 - Moderate support from prior consolidation lows moderate
📉 Resistance Levels:
- $0.25 - Immediate overhead resistance from recent swing high moderate
- $0.4 - Significant resistance from mid-January 2026 swing low turned resistance strong
Trading Zones (low risk tolerance)
🎯 Entry Zones:
- $0.175 - Potential low-risk long entry on confirmation of bounce from strong support, supported by positive audio sector fundamentals low risk
🚪 Exit Zones:
- $0.22 - Initial profit target at next minor resistance 💰 profit target
- $0.165 - Tight stop loss below key support to protect capital per my philosophy 🛡️ stop loss
Technical Indicators Analysis
📊 Volume Analysis:
Pattern: climactic spikes on downside moves
Elevated volume accompanying price declines confirms selling pressure and distribution
📈 MACD Analysis:
Signal: bearish
MACD line below signal line with expanding negative histogram, no bullish divergence visible
Applied TradingView Drawing Utilities
This chart analysis utilizes the following professional drawing tools:
Disclaimer: This technical analysis by Sarah Davis is for educational purposes only and should not be considered as financial advice. Trading involves risk, and you should always do your own research before making investment decisions. Past performance does not guarantee future results. The analysis reflects the author's personal methodology and risk tolerance (low).
Integrating these with royalty rails amplifies value. Synthetic audio bearing watermarks not only proves provenance but triggers automated payouts when licensed content proliferates. Watermarked. ai and peers demonstrate resilience: watermarks persist through 90% of common attacks, per tests. This reliability underpins conservative strategies in the generative AI surge.



No comments yet. Be the first to share your thoughts!