
Robust Watermarking for Synthetic Videos to Block Deepfake Editing and Ensure Royalty Tracking
In the shadowy realm of synthetic videos, deepfakes lurk like digital chameleons, morphing truth into deception with alarming ease. Traditional watermarks, once hailed as guardians of authenticity, crumble under sophisticated editing tools. Yet, a new breed of robust watermarking emerges, engineered to withstand deepfake manipulations while paving seamless paths for AI video royalty tracking. These deepfake resistant watermarks don’t just embed markers; they fortify content against erasure and enable creators to monetize their work through royalty rails for generative content.


Consider the stakes: videos generated by diffusion models flood platforms, indistinguishable from reality until malice intervenes. University of Waterloo research exposes how standard watermarks offer zero defense, as attackers strip them without algorithmic insight. Adobe’s TrustMark fights back with spatio-spectral tricks, but video demands more, temporal resilience against frame swaps or speed alterations. This is where innovation pivots from vulnerability to vigilance.
Why Synthetic Videos Demand Unbreakable Markers
Synthetic videos amplify deepfake risks because their pixel-perfect origins invite seamless edits. A face swap here, a voice overlay there, and provenance vanishes. Sources like Antispoofing Wiki advocate universal systems, yet removal attacks, from ML-trained erasers detailed in Rod’s Substack, persist. Imperceptible media markers must survive not just cropping or compression, but adversarial rewrites.
Enter the core challenge: embedding without visual scars while decoding under duress. Hugging Face’s AI Watermarking 101 outlines pros and cons, but videos add layers, audio sync, motion blur, frame interpolation. ScoreDetect’s streaming techniques hint at piracy wards, yet deepfakes evolve faster. Creators and platforms crave synthetic video watermarking that links back to origins, fueling royalty flows amid generative AI’s boom.
VideoMark and Pioneering Temporal Defenses
Leading the charge is VideoMark, a training-free marvel from recent arXiv breakthroughs. It injects pseudorandom error correction codes into video diffusion models, scattering uniform noise that defies detection. The Temporal Matching Module shines, extracting watermarks post-frame deletions or shuffles, crucial for deepfake countermeasures.
Quality holds firm; visuals remain pristine. This framework sidesteps retraining hassles, making it plug-and-play for developers. Imagine deploying deepfake resistant watermarks that laugh off temporal assaults, ensuring every clip traces to its AI forge.
5 Key Robust Watermarking Advancements
-
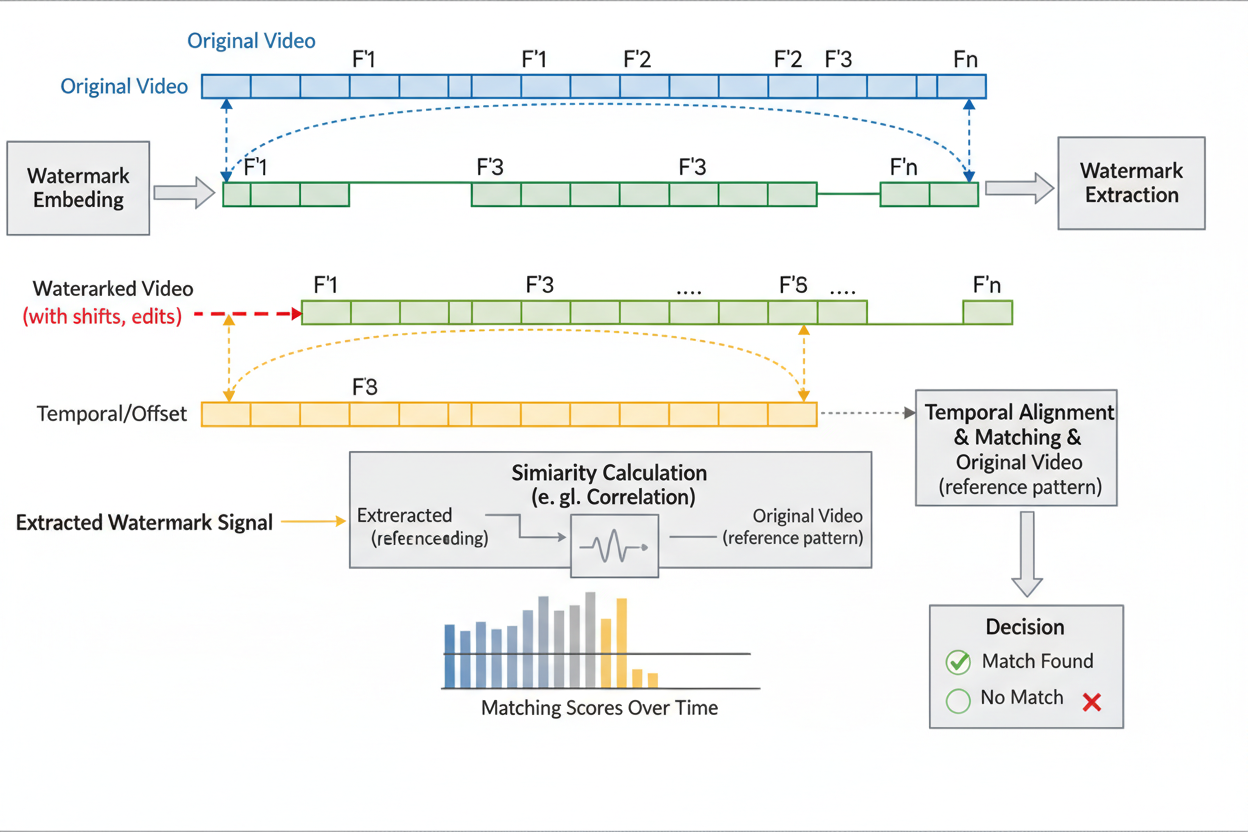
VideoMark (temporal matching): Training-free framework embeds watermarks into video diffusion models using pseudorandom error correction codes. Features Temporal Matching Module for robust extraction under frame deletion attacks. arxiv.org
-

V2A-Mark (audio-visual sync): Combines video-into-video steganography with deep robust watermarking for invisible visual-audio watermarks. Enhances localization accuracy via temporal alignment. arxiv.org
-

LVMark (frame consistency): Introduces watermark decoder learning consistency between adjacent frames in video diffusion models. Embeds in low-impact layers for quality preservation. Project site
-

DiffMark (diffusion guidance): Diffusion-based framework guides sampling with facial images and watermarks. Uses pre-trained autoencoder for robustness against deepfakes. sciencedirect.com
-

ReelMind (crypto signatures): Embeds imperceptible cryptographic signatures tied to generative process for unique video attribution and anti-piracy protection. reelmind.ai
V2A-Mark: Audio-Visual Synergy Against Edits
Building on this, V2A-Mark fuses video-into-video steganography with deep robust embedding. Invisible watermarks lace both frames and audio, pinpointing manipulations via temporal alignment. Degradation prompt learning bolsters decoding amid noise or crops, ideal for AI video royalty tracking.
Stakeholders gain localization precision, spot the tampered lip-sync instantly. DoveRunner notes watermarking’s crime-curbing potential; V2A-Mark realizes it by tying visuals to soundtracks, thwarting disembodied deepfakes. Council on Foreign Relations urges tiered integrity; these tools deliver, layering markers for multi-faceted verification.
LVMark’s Consistency Edge in Diffusion Eras
LVMark tackles a video Achilles’ heel: temporal inconsistency. Its decoder learns adjacent-frame harmony, embedding in low-impact layers. Malicious attacks falter as messages decode accurately, quality intact. For royalty rails, this means uninterrupted attribution chains, even post-edits.
DiffMark complements by conditioning diffusion on faces and watermarks, denoising progressively with autoencoder armor. ReelMind’s cryptographic signatures bind to generation, invisible yet ironclad. Together, they form an arsenal where imperceptible media markers not only block edits but automate payouts, transforming threats into revenue streams.
These techniques don’t stop at defense; they unlock proactive monetization. By embedding royalty rails for generative content, creators can automate licensing enforcement. Once a watermarked video spreads, detection tools scan platforms, verify origins, and trigger micropayments. No more chasing pirates; royalties flow via smart contracts, tied to every view or derivative use.
Integrating Deepfake-Resistant Watermarks with Royalty Systems
Picture this: a viral synthetic clip hits social feeds. Behind the scenes, VideoMark’s Temporal Matching Module confirms integrity, while V2A-Mark flags audio tampering. Platforms query the watermark hub, pulling creator metadata and usage rights. LVMark ensures frame-by-frame consistency, blocking edited clones from evading checks. DiffMark’s diffusion conditioning makes facial deepfakes detectable at source, and ReelMind’s signatures provide cryptographic proof for disputes.
This ecosystem thrives on interoperability. Watermarks encode not just IDs, but smart contracts addresses, view thresholds, and split ratios for collaborators. Emergent Mind’s techniques evolve here, verifying authenticity invisibly. When edits occur, partial decoding still reveals origins, deducting royalties proportionally. It’s a self-policing network where synthetic video watermarking fuels sustainable AI creativity.
Comparison of Robust Watermarking Techniques
| Technique | Key Strength | Attack Resistance (Temporal/Visual/Audio) | Quality Impact | Royalty Fit |
|---|---|---|---|---|
| VideoMark | Temporal Matching | High/High/Medium | Low | Excellent |
| V2A-Mark | Audio-Visual Sync | High/High/High | Low | Superior |
| LVMark | Frame Consistency | Medium/High/Medium | Minimal | Strong |
| DiffMark | Diffusion Guidance | High/Very High/Medium | Low | Good |
| ReelMind | Crypto Signatures | High/High/High | None | Perfect |
Yet robustness demands vigilance against evolving threats. Substack’s Rod warns of ML removal attacks, training models to excise markers. These new frameworks counter with error-correcting codes and spectral diversity, forcing attackers to degrade quality unacceptably. University of Waterloo’s UnMarker exposes weaknesses, but VideoMark sidesteps by avoiding predictable patterns. Opinion: true resilience lies in multi-layering, combining visual, audio, and metadata embeds for redundancy.
Real-World Deployment: From Devs to Enterprises
For developers, integration starts simple. Plug VideoMark into Stable Video Diffusion pipelines, no retraining needed. Media companies scale with ReelMind’s generative bindings, securing enterprise outputs. Indie creators? API calls embed markers pre-upload, linking to royalty dashboards. ScoreDetect’s streaming parallels apply: track cascades across chains, from TikTok clips to NFT mints.
Challenges persist, like computational overhead, but optimizations keep it lightweight. Antispoofing’s universal push aligns; these tools standardize detection APIs. Hugging Face tools accelerate prototyping, blending open-source with proprietary edges. The payoff? Creators reclaim value, platforms reduce liability, regulators gain audit trails.

Forward-thinking platforms already experiment. Imagine YouTube scanning uploads natively, flagging unmarked synthetics, or Discord bots verifying clips in real-time. Deepfake crimes, as DoveRunner highlights, plummet when origins stick. Adobe’s TrustMark inspires, but video-specific advances like LVMark push boundaries further.
Future-Proofing Content in the Generative Era
AI Watermark Hub stands at this frontier, offering deepfake resistant watermarks with seamless royalty rails. Our platform unifies VideoMark-style embedding, V2A detection, and automated tracking, empowering you to protect and profit. As diffusion models proliferate, imperceptible markers become table stakes, not options.
Stake your claim now. Deploy robust AI video royalty tracking, watch edits fail, and royalties accrue. The deepfake shadow fades when vigilance embeds at creation. Creators, developers, rights holders: this is your arsenal for thriving amid synthetic surges.



